
导读
以下内容由 NOVSITA 结合 X / 社交媒体公开内容 整理,仅作阅读与研究参考。
重点
- 申明:本文来自𝕏@Shubham Saboo 大神,我整理翻译中文!大家可以关注一波!
- 我唯一做的事,就是跟它们说话。
备注
涉及规则、收益或判断的部分,请以 Berryxia.AI 的原始表达与最新官方信息为准。
申明:本文来自𝕏@Shubham Saboo 大神,我整理翻译中文!大家可以关注一波!
我唯一做的事,就是跟它们说话。
不是调prompt,不是换模型,不是重构架构。就是说话,给反馈,看着它们把内容记下来。

申明:本文出自 海外大神 Shubham Saboo ,可以关注一波!x:https://x.com/Saboo_Shubham_
40天前,我的内容智能体写推文还堆表情包和hashtag,研究智能体把有价值的信息淹没在噪音里。我花在纠错上的时间,比自己直接做还多。
今天,Kelly用我的语气起草内容,Dwight每天早上送来7条故事,每一条都值得读。8个智能体24小时运转。我打开Telegram,看看草稿,喝杯咖啡。
第1天和第40天用的是同一个模型。区别在于一堆每周都在变丰富的Markdown文件。
这就是那套文件体系。
先搞清楚一件事
智能体不会因为你用得更久而变聪明。但它周围的文件会变得更丰富、更精准、更贴合你的需求。这些积累的上下文才是护城河。

很多人花大量时间调prompt、换模型、研究各种编排框架。但真正的差异不在模型,在于文件体系。
没有消息队列,没有数据库,没有复杂的编排框架。整个系统就是磁盘上的Markdown文件。文件系统本身就是集成层。
听起来简陋?看完你就知道为什么这比任何框架都管用。
三层架构,一目了然
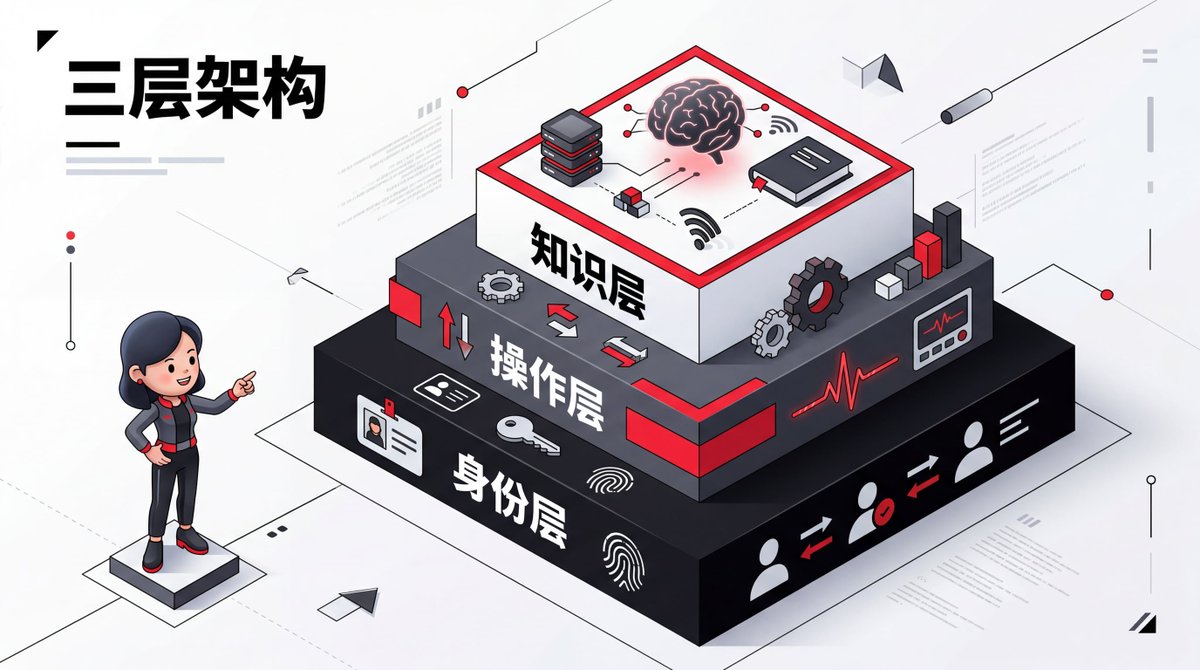
整个操作系统由三层构成:
图1:三层文件架构
每一层解决一个核心问题:
层级核心问题文件身份层这是谁?为谁服务?SOUL.md、IDENTITY.md、USER.md操作层怎么干活?怎么自愈?AGENTS.md、HEARTBEAT.md知识层学到了什么?MEMORY.md、每日日志、共享上下文
下面逐层拆解。
第一层:身份层
SOUL.md —— 智能体是谁?

这是智能体的”人格文件”。定义身份、职责、行为方式。
一个研究智能体Dwight的例子:
SOUL.md(Dwight)
IDENTITY.md —— 快速参考卡
SOUL.md是完整人格,IDENTITY.md是名片。
IDENTITY.md
文件很小,但当你同时跑8个智能体时,这个设计会大幅提升体验。这也是智能体在Telegram给你发消息时显示的内容。
USER.md —— 智能体服务的对象
每个智能体都需要知道它在帮谁。
USER.md
个人细节比你想象的更重要。时区意味着智能体不会在凌晨3点给你安排事情。饮食偏好意味着当Pam为团队晚餐起草通讯时,不会推荐牛排馆。这些细节会产生复利效应。
写一次,所有智能体都来读。
第二层:操作层
AGENTS.md —— 行为规则

SOUL.md定义智能体是谁,AGENTS.md定义它如何运作:会话启动流程、文件读取顺序、记忆管理、安全规则。
所有智能体继承的根级AGENTS.md:
AGENTS.md
智能体在会话之间没有记忆,每次都从零开始。如果一个纠正没有落入文件,下次会话它就不存在了。AGENTS.md明确了这一点,确保智能体把一切都写下来。
每个智能体可以在此基础上扩展自己的规则。Kelly的AGENTS.md就添加了6个额外文件:写作风格指南、帖子格式参考、真实案例、每日任务……
HEARTBEAT.md —— 自愈机制
智能体团队是基础设施,基础设施会出故障。
Monica的HEARTBEAT.md监控两件事:
- 浏览器是否存活 — Dwight的情报扫描依赖它
- 定时任务是否执行 — 如果漏跑,Kelly和Rachel就会基于过时情报工作
第三周我就被坑过。调度器有个bug,任务在队列里推进,但从未真正执行。我好几个小时都没发现。之后我才建了心跳机制,把故障模式纳入监控。
第一天不需要这个,在你第一次遇到故障之后再建。你会清楚地知道该监控什么,因为你已经亲身感受过什么会崩。
第三层:知识层
这是真正有效的记忆系统——基于文件的三级体系。

第一级:MEMORY.md(精华长期记忆)
不是原始日志,不是所有发生过的事,而是真正重要的内容。
注意”血泪教训”和”错误示范”这两节。Monica删了一个项目文件夹,这个错误从此永久写入她的长期记忆。她再也不会重蹈覆辙。
一次纠正,存储一次,防止同样的错误在未来每次会话中重演。仅这一节,就比任何prompt工程指南都值钱。
第二级:每日日志(原始记录)
每日日志是原材料,MEMORY.md是精炼产品,两者缺一不可。
维护规则:每日日志积累得很快,不修剪的话智能体的上下文会膨胀。Kelly的日志一度达到161,000 tokens,输出质量急剧下降,不得不压缩到40,000。每次只加载今天和昨天的日志。
第三级:shared-context/(跨智能体知识层)
这是最新加入的部分,也是改变一切的部分。
THESIS.md是我当前的思维框架:我关注什么,我已经写了什么,还有哪些空白。Dwight读它来确定研究优先级,Kelly读它来匹配我的思路。每个智能体都对齐到同一个真相来源。
FEEDBACK-LOG.md是跨智能体纠正层。当我告诉Kelly”不要用破折号”,这条反馈同样适用于Rachel、Ryan和Pam。与其逐个纠正四个智能体,我只写一次,所有人都来读。
这单一改变节省的时间,比我做过的任何prompt优化都多。
智能体如何协作
没有API调用,没有消息队列,只有文件。
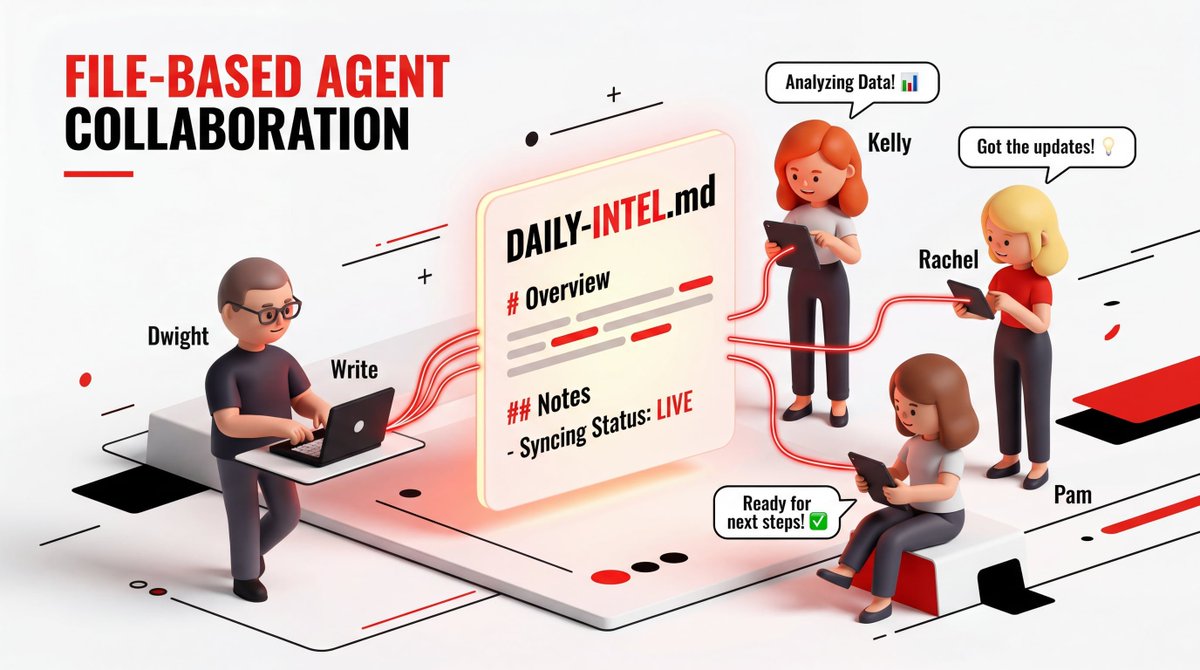
Dwight把研究写入intel/DAILY-INTEL.md,Kelly读,Rachel读,Pam读。协作就是文件系统。
图2:基于文件的协作流程
单写者原则:永远不要让两个智能体同时写同一个文件。把每个共享文件设计成一个写者、多个读者。这能防止你本来需要调试的所有协调冲突。
调度让这一切成为可能:Dwight在早8点和下午4点运行,Kelly和Rachel在下午5点运行。Dwight先跑,因为所有人都依赖他的输出。顺序搞错了,下游智能体读到的就是过时或空白的文件。
完整目录结构
为什么这套方法有效
文件不是静态的,它们在进化。
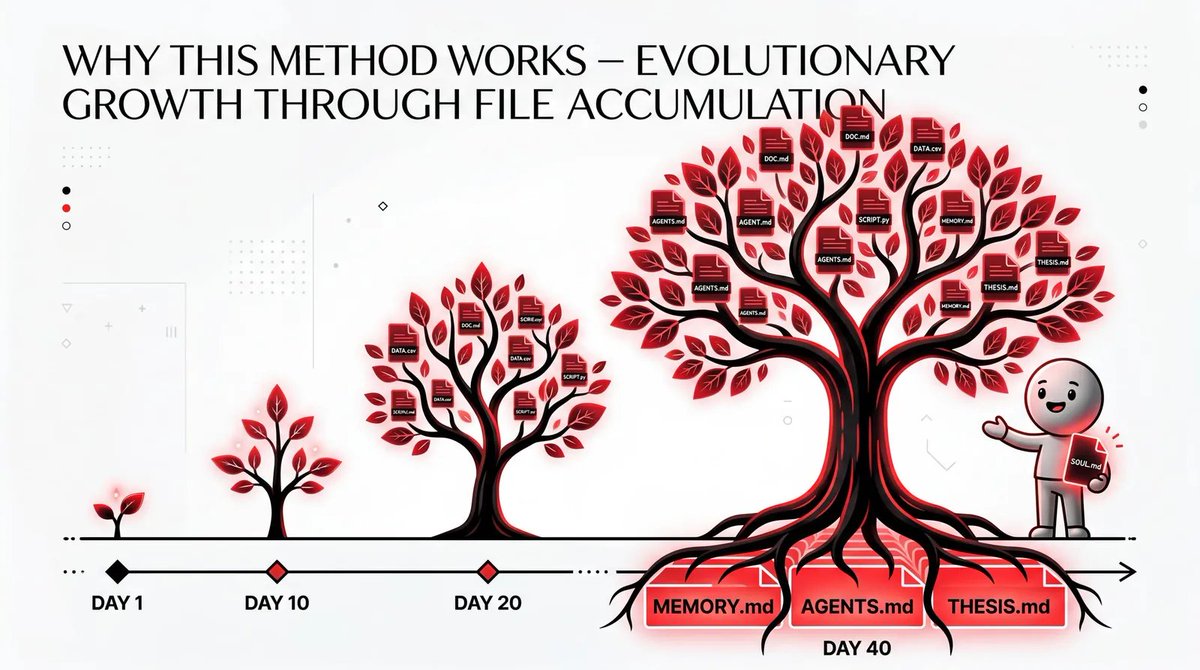
Kelly的SOUL.md第一天只是个粗略草稿。到第40天,它已经有了具体的语气示例、她自己写的被否决模式列表,以及一个”永远不要再建议”的专区。
Dwight的原则第一天写的是”找到热门趋势”。第10天变成了”如果Alex今天无法对此采取行动,跳过”。第20天,他又加入了核实步骤。
共享上下文层直到第20天才存在。那时我在对多个智能体重复同样的纠正。后来我建了THESIS.md和FEEDBACK-LOG.md,突然间,一次纠正就能传播到所有地方。
第1天和第40天的模型是一样的。它不会因为你用得更久而变得更聪明。
但围绕它的文件变得更丰富、更精准、更贴合你的具体需求。
这些积累的上下文才是护城河。没有人能通过使用同一个模型来复制它。
你要靠每天出现、与智能体对话来赢得它。
如何开始(不要试图在一个周末搭完)

时间行动今天安装OpenClaw,写一个SOUL.md、IDENTITY.md、USER.md。挑最重复的日常任务,设置定时任务让它跑起来3天后开始给出具体反馈,确保反馈落入记忆文件,而不只是停留在聊天记录里1周后创建AGENTS.md,定义会话启动流程,添加记忆管理规则2周后开始写MEMORY.md,回顾每日日志,把反复出现的纠正蒸馏成永久条目。
这时你会感受到复利开始发生3周后添加第二个智能体,建立基于文件的协作。随着模式涌现,添加角色专属指南大约同时建立共享上下文层。用THESIS.md记录当前思考,用FEEDBACK-LOG.md管理跨智能体纠正4周后在你第一次遇到故障之后,添加HEARTBEAT.md
写在最后
你唯一需要做的,就是与你的智能体对话。文件会完成其余的一切。

不是调prompt,不是换模型,不是重构架构。
就是说话。给反馈。看着它们把内容记下来。
然后有一天你打开Telegram,看看草稿,喝杯咖啡。
你的智能体已经学会了怎么帮你工作。
参考:Shubham Saboo《How to Build OpenClaw Agents That Actually Evolve Over Time》
来自:https://x.com/Saboo_Shubham_/status/2027463195150131572
整理翻译:Berryxia.ai
交流:358848136
来源
作者:Berryxia.AI
发布时间:2026年3月3日 11:08
来源:原帖链接
编辑评论
这篇《X 导入:Berryxia.AI – OpenClaw养成记,从0开始!安装后必看!(40天实战经验+含角色提示词)》来自 X 社交平台,作者为 Berryxia.AI。从内容完整度看,原文给出的关键信息密度较高,尤其在核心结论和行动建议上有较强的可执行性。申明:本文来自𝕏@Shubham Saboo 大神,我整理翻译中文!大家可以关注一波! 我唯一做的事,就是跟它们说话。 不是调prompt,不是换模型,不是重构架构。就是说话,给反馈,看着它们把内容记下来。 40天前,我的内容智能体写推文还堆表情包和hashtag,研究智能体把有价值的信息淹没在噪音里。我花在纠错上的时间,比自己直接做还多。 今天,Kelly…。对读者来说,它最直接的价值不是“知道一个新观点”,而是能快速看到该观点背后的条件、边界和潜在代价。 如果把这篇内容拆成可验证的判断,至少包含以下层面:申明:本文来自𝕏@Shubham Saboo 大神,我整理翻译中文!大家可以关注一波!;我唯一做的事,就是跟它们说话。。这些判断中,结论部分往往最容易传播,但真正决定实用性的,是前提假设是否成立、样本是否足够、时间窗口是否匹配。我们建议读者在引用这类信息时,优先核对数据来源、发布时间和是否存在平台环境差异,避免把“场景化经验”误当作“普遍规律”。 从行业影响角度看,这类内容通常会对产品策略、运营节奏和资源投入产生短期引导作用,尤其在 AI、开发工具、增长和商业化等主题里更明显。站在编辑视角,我们更关注“它是否能经受后续事实检验”:一是结果能否复现,二是方法能否迁移,三是成本是否可承受。来源为 x.com,建议读者将其作为决策输入之一,而不是唯一依据。 最后给出一个实操建议:如果你准备据此行动,可以先做小范围验证,再根据反馈逐步扩大投入;若原文涉及收益、政策、合规或平台规则,请以官方最新公告为准,并保留回滚方案。转载的意义在于提高信息流通效率,但内容价值真正形成于二次判断与本地化实践。基于这一原则,本文配套的编辑评论会持续强调可验证性、边界意识与风险控制,帮助你把“看到的信息”变成“可以落地的认知”。