导读
AI 浪潮下,连马斯克都难逃焦虑,普通人更是在层出不穷的新概念中疲于奔命。马识途通过复盘自身经历指出,当前的 AI 术语大爆发与当年的大厂黑话如出一辙。与其盲目追逐每一个技术热点,不如回归真实的需求场景。本文为深陷“工具焦虑”的职场人提供了一份清醒的避坑指南。
重点
- 警惕 AI 圈的“黑话”炒作,许多复杂概念本质上是技术普及初期的包装,普通用户无需被名词门槛吓退。
- 需求是学习的第一动力,脱离实际工作和生活场景去死磕 AI 工具,往往只会增加无效的心理负担。
- 区分专业开发者与普通用户的学习路径,按需索取、结合具体痛点进行实践,才是对抗技术焦虑的最优解。
备注
技术迭代的阵痛期总会伴随信息过载。NOVSITA 编辑认为,AI 最终会像鼠标键盘一样隐入烟尘,成为基础生产力。与其担心被淘汰,不如先解决手头那件麻烦事。别让工具成了你的主人,保持节奏比追赶潮流更重要。
纳瓦尔曾在2023年4月2号发过一条推文:
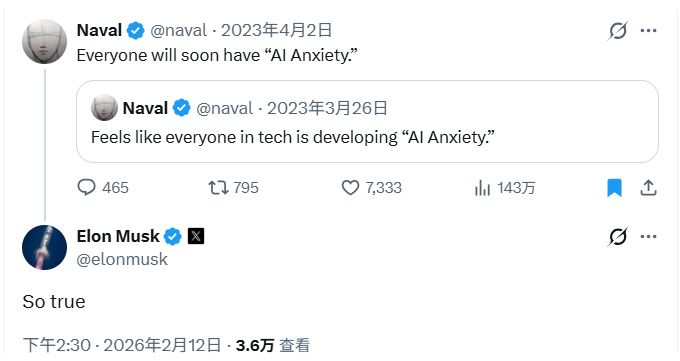
Everyone will soon have “AI Anxiety.”
不久之后,每个人都会有“人工智能焦虑”。
有趣的是,马斯克在2026年2月12日评论了这条帖子:
So True
太对了
马斯克在这个时间点回复这条推文,不知他具体在焦虑些什么?
但连马斯克都有AI焦虑,可见其普遍性!
如今很多人都有AI焦虑。
离普通人比较远的、宏大叙事的那些东西我们就不谈了,只说说AI学习焦虑。
“AI教主”黄仁勋说:AI不会淘汰人,但会用AI的人会淘汰不会用AI的人。
如今AI技术类似于上世纪90年代的计算机、2000年之后的互联网,成为人们必须学习的重要技能。
但是,AI技术现在迭代更新比较快,各种新概念、新工具层出不穷。试举几例:
代理(agent)、子代理、提示词(prompt)、上下文、记忆、模式、权限、工具、插件、技能(skills)、钩子、MCP、LSP、斜杠命令、工作流、IDE集成。。。最近又出了个龙虾OpenClaw 🦞,火的一塌糊涂
想不想当年互联网大厂的“黑话”:
抓手、闭环、赋能、矩阵、打法、落地、对齐、拉齐、颗粒度、体感、心智、破圈、下沉、同步、对焦、复盘、沉淀、输出、迭代、跟进、推进、兜底、击穿、优先级、资源倾斜、权责利、向上管理、拿结果、背指标、通晒、中台、前端、后端、GMV、DAU、MAU、渗透率、转化、链路、抓手位、增量、存量、ROI、务虚、务实、共识、碰撞、拉通、优化、毕业、活水、扁平化、狼性。。。
我也曾经有过很强的AI焦虑,一度追逐各种AI相关最新新闻和最新技术。
但发现焦虑没有意义,而很多时髦的词汇也只是炒作概念而已。
一项技术要普及,触达更多的人,其概念和用法就不能过于复杂。
得简单和易于理解,就像当年大家用电脑和互联网一样,入门门槛其实就是打字和会用鼠标,再就是了解一些菜单和图标的基本功能。
对于专业的程序员来讲,可能以上列举的AI相关概念都要理解。但对于普通用户来说,关键是结合工作和生活场景的应用。
需求是学习之母。对学习技能来说,关键看有没有刚需场景,有刚需场景很快就能学会。创造不出需求场景,学起来会很吃力
对普通人,焦虑,紧追最新的工具、最新的信息,大可不必,按需学习、结合自己生活工作场景学习即可。
现在AI的各种概念和工具,程序员们的刚需场景比较多,普通人还是少了一些。AI很有用,我也在用AI的各种功能,但我只是按需学习和使用。
我原来也有很强的AI焦虑,但现在已经没有了。
你有没有AI学习焦虑?欢迎留言分享!
#AI焦虑
深度编辑评论
如果只把这类内容当作热点信息消费,它很快就会过期;但如果把它转换成可执行认知框架,价值会显著提升。围绕本文主题,我们建议把结论拆分为“事实层、判断层、决策层”。事实层用于验证真假,判断层用于理解作者立场,决策层才是你真正要投入资源的部分。三层不分开,最常见的问题就是把观点当结论、把情绪当证据。
在落地层面,建议采用“72小时小闭环”方法:第一天完成信息清洗与对照,第二天做小规模验证,第三天复盘并形成可复制动作。这样可以快速识别文章中的高价值信号,避免因为单条信息热度高就过度放大。对于个人创作者,可以将结论转化为选题、流程、工具三类动作;对于团队运营,可以转化为指标、角色、节奏三类动作。
从风险角度看,社交平台内容天然存在叙事偏差。为了降低误判,至少做三项校验:一是时间校验,判断结论是否依赖短期事件;二是样本校验,判断观点是否来自单一案例;三是反例校验,主动寻找不支持该结论的证据。只有三项都通过,才建议进入中长期决策。否则,最稳妥的方式是先观察、再验证、后投入。
本文新增这部分评论的目的,是把转载内容从“可读”提升到“可用”。我们后续会持续更新:当新数据出现、原假设被推翻、或上下文发生变化时,优先修正方法和边界,而不仅仅补充结论。长期看,真正提高内容质量的不是篇幅,而是可验证性、可执行性和可复用性。
如果你要把本文结论应用到实际工作,建议先设定一个明确场景和单一目标,例如“提升选题命中率”“缩短验证周期”“减少错误投入”。然后将文中要点写成检查清单,每周固定复盘一次。这样可以确保文章信息真正沉淀为方法资产,而不是一次性的阅读刺激。
编辑评论
现在的科技圈,如果不随口蹦出几个像 MCP、Agent 或者 Workflow 这样的缩写,好像都没法正经聊天了。马识途在 X 上分享的这段感悟,其实戳中了一个当下最隐秘也最普遍的痛点:我们到底是在学 AI,还是在被 AI 圈子新造的“黑话”霸凌? 看到原文提到马斯克在 2026 年回复纳瓦尔,这显然是个时间线上的笔误,或者某种带有预言性质的调侃,毕竟我们还没过上 2026 年的日子。但抛开这个细节不谈,纳瓦尔那句“每个人很快都会有 AI 焦虑”确实精准预言了当下的社会心理。这种焦虑的本质其实是“技术通胀”。就像马识途对比的那样,当年的大厂黑话把简单的业务逻辑包装成“赋能、闭环、沉淀”,现在的 AI 圈子也正在经历这个过程。把一个简单的自动化脚本叫作“智能体”,把一段对话要求叫作“提示词工程”,这种概念的堆砌,除了能让卖课的博主多收几份学费,对普通用户解决实际问题并没有太大帮助。 从产业角度来看,这种“黑话化”其实是技术普及初期的典型乱象。厂商为了体现差异化,拼命发明新词;开发者为了显得专业,不断叠加架构。这导致了一个很荒诞的现状:技术迭代快得让人喘不过气,但真正落地到普通人工作流里的工具,其实还是那几个。大家在社交媒体上疯狂转发“必看的 50 个