
导读
以下内容由 VIPSTAR 结合 X / 社交媒体公开内容 整理,仅作阅读与研究参考。
重点
- 深夜凌晨2点,我刚准备睡觉。
- 然后,GPT-5.4,突然发布。
备注
涉及规则、收益或判断的部分,请以 数字生命卡兹克 的原始表达与最新官方信息为准。
深夜凌晨2点,我刚准备睡觉。
然后,GPT-5.4,突然发布。
一下子激动的睡不着了。
真的,这真不是我天天咋咋呼呼啥的,我真的也很少会用激动的睡不着觉这种表述。
这是因为,我一直在等正式版的GPT-5.3或者GPT-5.4,来作为我的OpenClaw的首选模型。
理由特别简单,因为现代世界三十年,本质上基层都是代码,我们现在看到的关于计算机和互联网的一切,几乎都建立在代码的基础之上。
所以你可以理解为,代码能力,在很多时候,就代表着Agent能力的一根粗壮的腿。
一个优秀的Agent基座模型,在我的理解里,一般来说,需要三种都很强:
代码能力、世界知识、多模态理解。
当你这三个都能SOTA的时候,你几乎必然就是最牛逼的Agent模型,当然,还有一个重要的因素,就是价格。
在过去,Claude Opus 4.6,几乎就是Agent模型的代名词,因为代码、世界知识都很强,多模态能力虽然比不过Seed 2.0和Gemini 3.1 Pro,但是在一些场景里面,也够了,因为现在的Agent,跟现实物理交互还没有那么多,那个已经是具身智能的范畴了。
而我过去很喜欢的GPT-5.3-Codex,代码能力确实强,在做任务执行的时候,那简直就是指哪打哪。
但是最大的问题,这玩意是一个编程特化模型啊,世界知识就是一坨屎,连GPT-5.2都不如,所以OpenAI当时也是没办法,为了跟Claude打一打,只能加个Codex的后缀给放出来了。
所以你会发现,在规划能力上,是完全比不过Claude Opus 4.6的,但是最大的问题,其实还是因为世界知识的问题,就导致这玩意。
它说天书,讲的那些话,真的,我不是程序员出身,我看那个话,看的就真的超级费劲。
就比如说,我让他之前对我的一个AI热点网站的项目进行审查,主要就是review一下我的文档规范和我整个代码库。
然后,这哥们写的文档,我尼玛。。。

你再对比一下Claude Opus 4.6写的。

对比起来应该一目了然。。。
就是因为这玩意不说人话,世界知识也不行,所以,只是在Codex里面用用还好,但是你要是把它接到你的OpenClaw里面,去当做默认模型,你就知道啥叫灾难了,这哥们几乎没有人味,说起话来我想揍他。
所以我当时试了一下,就直接弃了,还是在我的OpenClaw里面,用的Claude Opus 4.6和Sonnet 4.6,做了一下场景调用。
那为啥说,我很期待GPT-5.4呢。
因为,Claude哪都好,但是,它贵啊!!!
它真的好贵啊!!!!!!
而且因为Anthropic这个呆逼,它把OpenClaw给疯了,所以我订阅的Claude的Max Plan的额度,是完全不能给OpenClaw用的,只能在Claude Code用,你想在OpenClaw上用,只能硬接API Key用。
但是大家都知道,Claude的API有多贵,那根本不是我们这种穷逼团队能用的起的,小规模用用还好,大规模用那公司直接破产了。
之前还有一条路是用反代,把Google家的Antigravity里面的Claude额度用插件代理出来,扔给OpenClaw用。
但是后面Google开始大批量封号,导致也没办法用了。
我过年的时候Google账号还被封了,被迫用AI去给Google写了一份声泪俱下的邮件。
我说我错了,我再也不会了。
后面Google才给我解封,但是反代肯定是用不了了。
而OpenAI就不一样了,最开始Claude疯狂封OpenCode账号的时候,OpenAI大手一挥,就站了出来,说我们不封,大家全力使用。
这是御三家里,唯一一个这么支持态度的,可以用第三方的工具,调用Codex的额度的。
那对OpenClaw自然也不例外了,也是几个顶级模型里面,为数不多的,可以直接走登录的,其他的都得用API。
真的,OpenAI这回真的是大善人。
还疯狂的给Codex加额度。

所以啊,Claude在OpenClaw里用,好是好,但是不能用订阅额度,只能用API,贵的一笔。
OpenAI的模型倒是可以用订阅额度,但是GPT-5.2代码又不行,GPT-5.3-codex又不说人话。
你看,要多别扭有多别扭。
而这一次,GPT-5.4来了!!!
终于把这个短板给补上了!
代码能力跟GPT-5.3-Codex齐平,世界知识比GPT-5.2还要强,还能使用订阅额度,20刀就可以用的超级爽。
你就说,这不是最适合OpenClaw的天选模型,还有谁是?嗯?
从今天开始,用OpenClaw的,都把默认模型切换到GPT-5.4去,真的,信我。
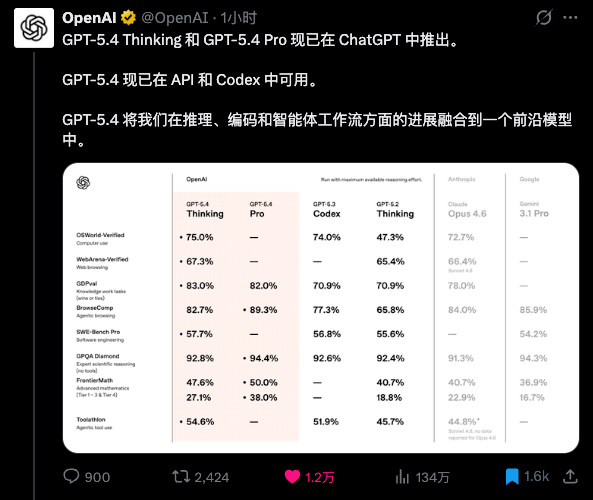
回到GPT-5.4,老规矩,先看跑分。
就很爽。
先看最关键的几个。
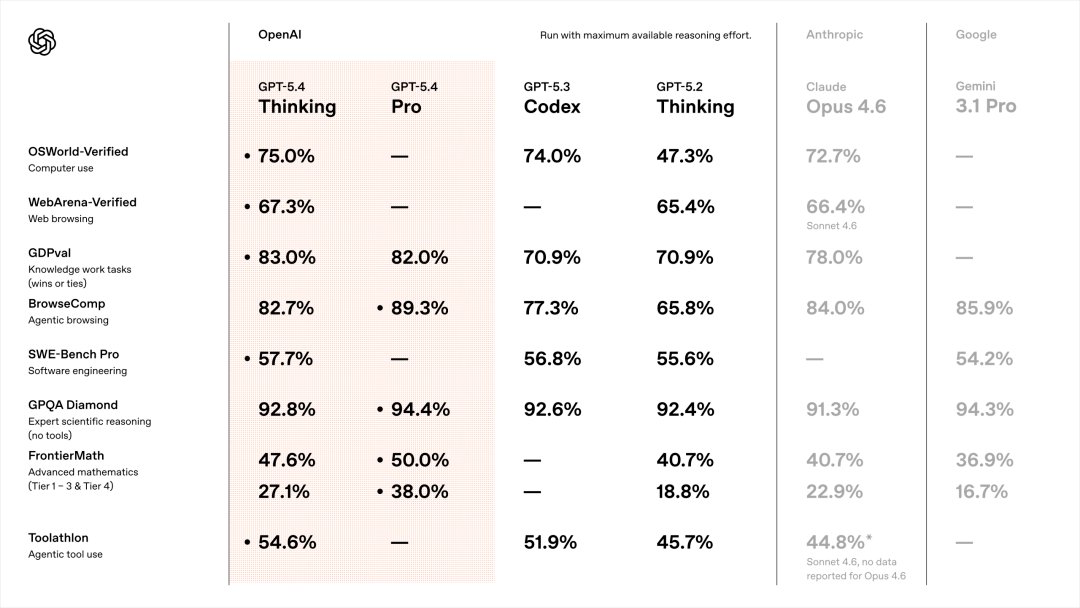
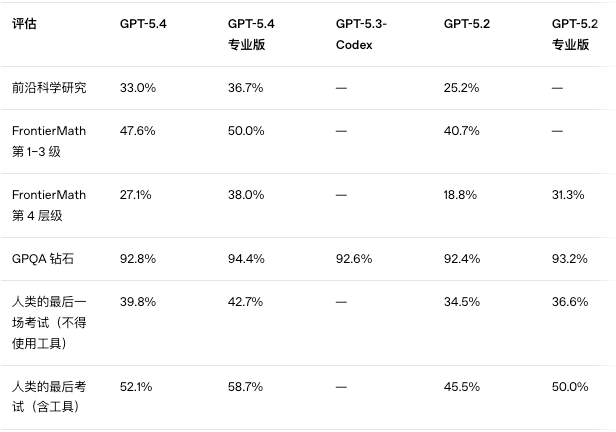
GDPval:83.0%
这个是测AI在真实工作任务中表现的,包括金融、法律等44种职业的知识工作。
GPT-5.4 Thinking拿了83.0%,Claude Opus 4.6是78.0%,GPT-5.3 Codex是70.9%。
在真实业务场景里,GPT-5.4不只是会写代码,它还能跟你聊业务、聊金融、聊法律、聊各种专业领域的东西。
而且是用人话聊,不是用天书聊。
SWE-Bench Pro:57.7%
这个是测AI解决真实软件工程问题的,不只是Python,而是测四种编程语言。
GPT-5.4 Thinking拿了57.7%,GPT-5.3 Codex是56.8%。
基本持平。
这就是我最想看到的结果。
代码能力保住了GPT-5.3 Codex的水平,世界知识又补上来了。
OSWorld-Verified也是,75.0%。这个是测AI操作电脑的能力的,就是让AI像人一样,用鼠标点击、用键盘输入、在不同应用之间切换,完成各种任务。
GPT-5.4 Thinking拿了75.0%,超过了Claude Opus 4.6的72.7%,也保持了跟GPT-5.3-Codex的持平。
而且,GPT-5.4操作电脑的速度,快的离谱。
看下这个没有加速过的视频,会更直观。
ToolAthlon:54.6%
这个是测AI使用工具的能力的,也就是Agent能力的核心指标之一。
GPT-5.4 Thinking拿了54.6%,Claude Sonnet 4.6是44.8%。
差了将近10个点。
至于学术知识之类的,跟GPT-5.3-codex就没法比了,因为OpenAI自己也知道,所以,直接当时就没跑。
总之,翻译成大白话就是。
GPT-5.4 = GPT-5.3 Codex的代码能力 + 比GPT-5.2还强的世界知识 + 更强的工具使用能力 + 超级便宜的codex额度。
这四样加在一起,就是一个完美的OpenClaw天选基座模型。
然后还有几个很棒的特性更新:
- 100万token的上下文窗口。
这是GPT-5.4的一个大升级。
之前GPT-5.3的上下文窗口是40万token,GPT-5.4直接翻了一倍多,到了100万。
这对Agent来说太重要了。
因为Agent在执行任务的时候,需要保持对整个任务的上下文理解。如果上下文窗口不够大,Agent干着干着就会忘事儿,前面说的东西后面就不记得了。
100万token,基本上足够应对绝大部分的Agent任务了。
当然,OpenAI也不傻,他们说,超过27万token之后,你的额度就算两倍了。

不过因为Codex给的额度实在是太多太多了,所以即使是2倍,其实也还好。
- 原生计算机使用能力。
这个是GPT-5.4的另一个大卖点。
OpenAI说,GPT-5.4是他们第一个内置原生计算机使用能力的主线模型。
它在编写通过Playwright等库操作计算机的代码方面表现非常的出色,同时也能根据屏幕截图发出鼠标和键盘命令。
也就是代码和视觉齐飞,我感觉,这个小龙虾接入以后,就真的可以,直接用视觉,操控你电脑上绝大多数的软件了,真的,原生操控,想想都激动。
他们基于此,还发布了一个新的skills,叫playwright-interactive。
允许Codex同时以代码和视觉的两种方式,调试Web和Electron应用。
网址在此,大家可以自行安装。
https://github.com/openai/skills/tree/main/skills/.curated/playwright-interactive
- 支持了工具搜索。
以前呢,当模型被赋予工具时,所有工具定义都会预先包含在提示中。
对于拥有大量工具的系统,这可能会为每个请求增加数千甚至数万个token,而且绝大多数的时候,都毫无意义,平白无故的导致成本上升、响应变慢,并在上下文中充斥模型可能永远不会使用的信息。
所以呢,这次他们也支持了工具搜索,就是GPT‑5.4不再直接接收完整工具定义,而是接收一份可用工具的轻量列表以及工具搜索功能。
当模型需要使用某个工具时,它可以查找该工具的定义并在当时将其追加到对话中。
就非常像Skills渐进式呈现的方式,目的很简单,还是优化上下文工程。
OpenAI在自己测试完以后,发现工具搜索配置在保持相同准确率的同时将总体token使用量减少47%,这个就非常牛逼了。
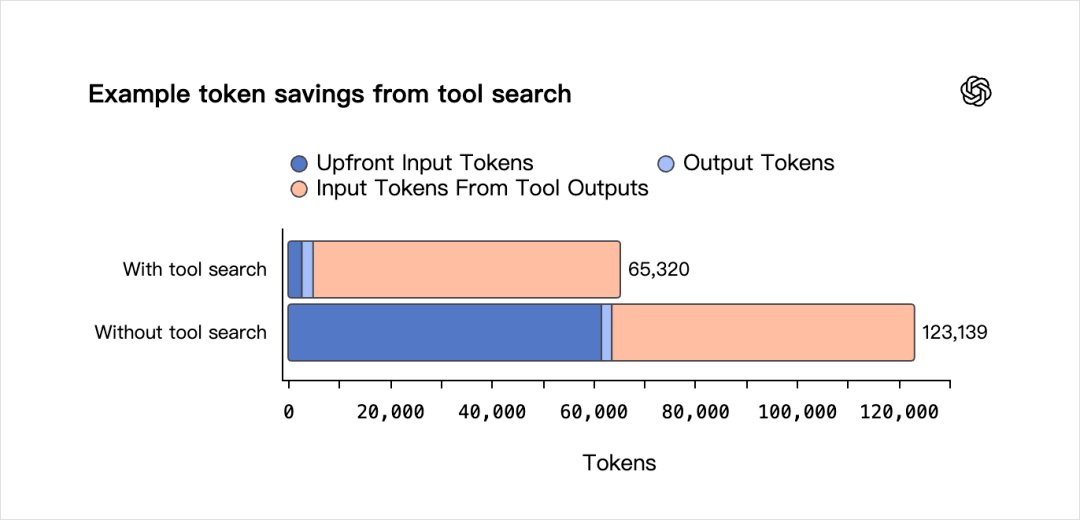
GPT-5.4 Thinking大概就是这样。
这次他们其实还发了个GPT-5.4 Pro,我就不细说了,反正就是一切都更牛逼了,但是对于大多数人来说,太贵了,也没啥大用,必须得200刀的Pro会员才能用。
API的整体价格还是得说一下,虽然大家大概率用的都会是订阅的额度。
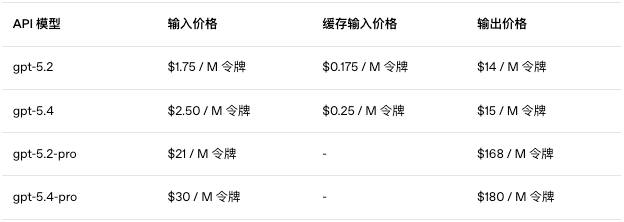
相比于GPT-5.2,价格是涨了的,但是还是比Claude Opus 4.6,便宜不少,Claude Opus 4.6的价格是$5/$25每百万token(输入/输出),GPT-5.4只有他们一半。
目前ChatGPT已经上线了。
Codex也已经支持了,我自己在Codex里面粗浅体验了一下。
首先扑面而来的,那自然是清新沁人的人话。。。
比如我让它去把OpenAI官网的视频给扒拉下来,你看看这个发言:“这种活最烦”,“省的跟Cloudflare互相折寿”。。。
还有这个。
真的,Codex的输出,我真的能看得懂了。。。
做出来的东西,前端审美有了不错的进步,但还是不如Opus 4.6和Gemini。

写作粗略测了一下,还是一股子莫名其妙的爱用排比句的诡异的味道。
奇奇怪怪。
然后有点可惜的就是,我等到了凌晨6点多,OpenClaw目前使用Codex登录的方式,还是没有支持GPT-5.4。
这就导致,我还是没有机会测GPT-5.4在小龙虾上的效果。
不过估计今天小龙虾就支持了。
因为社区里已经看到很多用户在催了,而且先行官们,都普遍反馈效果很好。
坐等支持,我真的已经迫不及待了。
又是开心的一晚。
如果你也在用OpenClaw,那记得OpenClaw支持了以后,把默认模型切换到GPT-5.4。
如果你还没用过OpenClaw,那正好,现在是一个很好的开始时机。
毕竟,有了GPT-5.4这个天选模型,体验只会更好。
2026年,真是疯狂的一年啊。
编辑评论
这篇《X 导入:数字生命卡兹克 – GPT-5.4深夜发布,最适合OpenClaw的天选模型登场了。》来自 X 社交平台,作者为 数字生命卡兹克。从内容完整度看,原文给出的关键信息密度较高,尤其在核心结论和行动建议上有较强的可执行性。深夜凌晨2点,我刚准备睡觉。 然后,GPT-5.4,突然发布。 一下子激动的睡不着了。 真的,这真不是我天天咋咋呼呼啥的,我真的也很少会用激动的睡不着觉这种表述。 这是因为,我一直在等正式版的GPT-5.3或者GPT-5.4,来作为我的OpenClaw的首选模型。 理由特别简单,因为现代世界三十年,本质上基层都是代码,我们现在看到的关于计算机和互联网的一切…。对读者来说,它最直接的价值不是“知道一个新观点”,而是能快速看到该观点背后的条件、边界和潜在代价。 如果把这篇内容拆成可验证的判断,至少包含以下层面:深夜凌晨2点,我刚准备睡觉。;然后,GPT-5.4,突然发布。。这些判断中,结论部分往往最容易传播,但真正决定实用性的,是前提假设是否成立、样本是否足够、时间窗口是否匹配。我们建议读者在引用这类信息时,优先核对数据来源、发布时间和是否存在平台环境差异,避免把“场景化经验”误当作“普遍规律”。 从行业影响角度看,这类内容通常会对产品策略、运营节奏和资源投入产生短期引导作用,尤其在 AI、开发工具、增长和商业化等主题里更明显。站在编辑视角,我们更关注“它是否能经受后续事实检验”:一是结果能否复现,二是方法能否迁移,三是成本是否可承受。来源为 x.com,建议读者将其作为决策输入之一,而不是唯一依据。 最后给出一个实操建议:如果你准备据此行动,可以先做小范围验证,再根据反馈逐步扩大投入;若原文涉及收益、政策、合规或平台规则,请以官方最新公告为准,并保留回滚方案。转载的意义在于提高信息流通效率,但内容价值真正形成于二次判断与本地化实践。基于这一原则,本文配套的编辑评论会持续强调可验证性、边界意识与风险控制,帮助你把“看到的信息”变成“可以落地的认知”。